

Rechtin on Ultraquality - Redundancy and Fault Tolerance
The Writings of a Complex Systems Architecture Legend
In his classic (but criminally overlooked) 1991 book "Systems Architecting, Creating and Building Complex Systems," Eberhardt Rechtin discusses technical, managerial and architectural responses to the challenge of building high quality systems. Despite being several decades old, 'modern' techniques like Lean manufacturing and progressive redesign do not escape him: after all, these are not new ideas. One is left in no doubt that, much like his contemporary W. Edwards Deming, Rechtin's heuristical approach represents a valuable lingua franca whose roots lie within innate mathematical thinking.
One architectural response discussed is redundancy, fault tolerance and fault avoidance, techniques widely applied today in the context of Cloud Computing and distributed systems. With those ideas in mind, Rechtin's observations and examples remain relevant and thought provoking today - after all, all complex systems obey the same mathematics, and therefore will be subject to the same heuristics.
His conclusion is an interesting one - that fault tolerance and redundancy tactics work best when applied to an already reliable system - underlying the need for us to continue to build quality in. With that in mind, he makes one further observation, that naval officers are taught that the more things you can do more than one way, the greater are the chances of survival. This would seem to be borne out today by the multi-faceted approaches being taken to complex systems testing, as outlined in Caitie McCaffrey's paper The Verification of a Distributed System. Perhaps the more ways you can verify a system, the greater the chance that it is correct.

Photo © NASA JPL Photograph Number P-1490B
Eberhardt "Eb" Rechtin, a former JPL employee, passed away on April 14, 2006. He was referred to by many as the "Father of the Deep Space Network" for his role in designing the network of space communication and tracking stations located around the world. The photo above was taken in September 1960, when he was Chief of the Electronics Research Section.
Architectural Response II: Redundancy, Fault Tolerance, and Fault Avoidance
Eberhardt Rechtin
One of the oldest responses to equipment failure is the provision of a redundant or a spare unit. Its algebra is deceptively simple. If the probability that one unit will fail is x and of another unit is y, then the probability that both will fail is the product, xy, provided that the failures are independent.
Thus, given two similar units that can fail randomly and independently, each with a failure probability of 0.01, then the probability that both will fail is 0.01 x 0.01 = 0.0001. If only one unit is needed for a mission, then by having two available, in this example, the failure probability has been reduced by a factor of 100.
Redundancy, as should be expected, if a favourite technique of raising system quality above that of the individual elements. It has been a mainstay of communications, network, aircraft and spacecraft design for many years.
In practice, the use of redundancy is more complex than it appears. The first complication comes with another bit of algebra. The probability of failure that either will fail is x + y - xy, or about 0.02 in the example just given. If both are needed, therefore, then mission failure rate is roughly twice as high as the failure rate of one unit.
This algebra comes to the fore when a third element is added, the device that decides which element is working and which is not. Unless that device is at least as reliable as the redundant pair, that is, 0.0001, then its failure rate determines the mission failure rate. For example, if its failure rate were the same as either unit, 0.01, then the mission failure rate would be worse than having no redundancy at all.
The second complication comes form the causes of the failures. If both units fail for the same reason at the same time, there is no true redundancy. Or, if mission failure is due to a different cause than assumed then the redundancy may have been applied to the wrong units, may not have been applied where needed, or may not have been cost-effective from a total system perspective.
The launch-vehicle example given earlier in this chapter shows why redundant guidance systems have been debated for many years; their contribution to the failure rate is just at the borderline of cost effectiveness for 0.94-success-rate vehicles.
The architectural question to be answered is, therefore: What is the purpose of the proposed redundant architecture and what failure mechanism is being countered?
Is it early failure (usually workmanship), long-term random environmental response, wearout, or occasional overload? The architectures and operating modes are different for the different cases.
Example: If the failure mechanism of concern is early failure, then close monitoring and quick, permanent switchover from a failed unit to an operating redundant one is the preferred procedure. The latter unit, having not experienced an early failure, is likely to last its full design lifetime. This technique has been one of the most useful ways of achieving the design lifetime of complex spacecraft.
Example: If the failure mechanism is long-term or wearout, then trend monitoring of a weakening operating unit should indicate when a redundant, previously unpowered unit should take over. But the switch from the weakened unit should be reversible. The redundant unit may fail early or emergency conditions may call for extending the device lifetime to far beyond the intended period.
Example: If the failure mechanism is the occasional overload of any one of a number of units, then the technique is usually a shared spare, available on demand, but unlikely to be called simultaneously by more than one overloaded element. The technique is common in communications networks, where spare channels and alternate routing are notably cost-effective. A single spare channel can often serve a dozen or more other channels on a given relay link.
Example: If a failure mechanism is common to a whole class of units mechanism is common to a whole class of units, then dissimilar redundancy may be called for, for example, the use of several, quite different, ways of achieving the same mission results. Navigation, for example, might be accomplished using either inertial, radio, stellar, or a combination of all. Command might be achieved using either radio or optical frequencies. Order wires for communications control might be either within or external to the main communications band. Different portions of a computer might be used to accomplish the same function. As they teach military officers at Naval Post Graduate School, the more things you can do more than one way, the greater are the chances of survival.
Redundant design becomes much more complex if multiple redundancy is needed. Consider the "cross-strapped" configuration of Figure 8-3, a simplified version of a launch-vehicle control system. The purpose of the configuration is to accomplish four different sequential functions, any of which could fail.
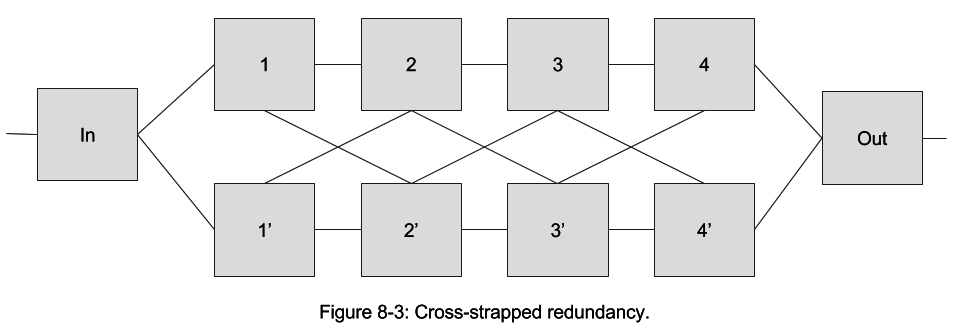
The two parallel strings, 1-4 and 1' -4', provide redundancy, but only if the correct connections are made at the right time. Making each connection depends upon knowledge of the status of all elements and connections, a complex machine-intelligence problem.
The configuration was implemented successfully, but the redundancy management element (not shown) turned out to be far more complex, more costly, and more demanding of computer capacity than anticipated. Certifying its operation was difficult. However, it did save a mission worth hundreds of millions of dollars. The cause of failure of the main unit was attributed to a computer upset triggered by a cosmic ray. The question remained, nonetheless, whether the same amount of time, effort, and expense spent making a single unit more radiation resistant might have been a better investment. The answer, as in most cases, depended on many factors: the other possible failure mechanisms, cost-effective measures that might be taken to prevent their occurrence, the criticality of the mission, and the client's tolerance for risk. In the end, it is a judgement call.
A more sophisticated approach than redundancy is fault tolerance—the capability to maintain control of the system, bound the effects of failures, and counter them so that system integrity is maintained.
Fault-tolerant design takes the approach that unit failure need not and should not result in complete mission failure. If the system can be kept under control, the effect of the unit failure on the mission can be limited.
Hydraulic-brake failure on an automobile can be partly compensated by the use of an emergency hand brake. The loss of an attitude-control sensor on a spacecraft can be detected quickly enough so that the spacecraft can be placed in a safe condition with its solar panels facing the sun to keep it from losing electrical power. Software bugs can be countered by stopping calculations when results go out of bounds.
Fault tolerance, like redundancy, requires control mechanisms—instruments to detect system status, decision devices, switches, multiple modes, and interconnections. Its use against unspecified faults is a poor strategy at best. It works best in systems that are inherently reliable, that is, the failure rate of the system to be protected must already be low or the protective elements will be so complex that they become a major cause of failure themselves.
A prerequisite of fault tolerance is, therefore, fault avoidance. If a fault, error, or failure mechanism can be avoided, it should be designed out first before fault tolerance techniques are considered. Avoiding faults through better components is certainly a preferred approach.
To sum up, fault-tolerant designs are indeed powerful approaches to very high-quality architectures. However, the basic reasons that they are used as deficiencies in system design or component quality. Unless the deficie well understood and unavoidable,
Fault avoidance is preferable to fault tolerance in system design.
Fault tolerance, when used, should be specific to fault type.
Excerpted from Systems Architecting, Creating and Building Complex Systems, Eberhardt Rechtin, Prentice Hall, 1991.
You might also be interested in these articles...
Lean Agile Architecture and Development
Posted in: agile architecturecd pipeline architecturecloud computingcomplex systems architecturecontinuous deliverydemingdevopsdistributed systems testingmicroservicesrechtinredundancy and fault tolerancesoftware architecturetestabilitytesting