

Architecting Continuously Testable Systems
Testability Quality Factor for Continuous Delivery in Digital Systems
TL;DR; When we architect systems using automated testing and test-first approaches, we quickly see testability constraints move to our system boundary. Low testability quality factor in external services is a key constraint on our ability to continuously prove our system is in a state of production readiness. We require external systems to mature, to establish a chain of specification, driving repeatable testability; systems must provide us with the ability to reliably emulate their state, to permit us to test to our boundary, and not beyond. In turn, systems must accept our specifications, and they must, in turn, push specification to their own boundaries.
I've spent the last few months on site with a large enterprize client, mentoring their mobile development teams around automated testing practices, helping them on their journey towards Continuous Delivery and Microservices architectures.
You might imagine that an 'enterprize' would struggle with the varied technological challenges presented by polyglot mobile stacks. In fact, no, we saw small, dedicated DevOps teams putting innovative pipeline infrastructure together - build and test-time environment sharding, continuous database deployment, virtual Mac build agents, and even 'grunt-style' end-to-end provisioning of pipelines and environments (great stuff!)
Somewhat surprisingly, we discovered that once software teams began to improve their technical practices (by covering the automation test pyramid [Cohn, 2010]), their testing constraints quickly moved to their system boundaries. A team's typical constraint was no longer the complexity of their polyglot pipeline infrastructure, but rather the degree to which their pre-existing service dependencies and frameworks had been architected for testability. Symptoms of this oversight were as follows -
- APIs and services exposed their consumers to fully connected, end-to-end shared environments; depending on the nature of a service's underlying state, tests were not repeatable, and availability was low
- Integration tests written against shared fixtures were typically brittle, slow, and lack of isolation meant that tests tended to exhibit low levels of verification, limiting their value to a simple litmus test of "the service is on"
- Few external API providers ran any form of consumer driven acceptance test; consumers we routinely broken in shared environments
- API providers didn't provide consumers with sample tests or permit pull requests against a shared acceptance test repository
- Some service teams no longer existed - we needed to raise support tickets to refresh shared data
- Shared data was frequently cannibalised by external teams, causing integration tests within pipelines to fail
- Few systems exposed realistic stubs or test fixtures, though some stub work had been done to plug system gaps in some environments
- Working across silos was a challenge where external teams had conflicting levels of technical practice adoption; it was not straightforward to ship a feature switch into a 'master' release branch
- Even though some API teams had payed close attention to architectural guidelines, those guidelines did not cover testability!
Quality Factor goals for Continuous Delivery
In their book Continuous Delivery, Jez Humble and David Farley talk about the need to 'create a repeatable, reliable process for releasing software' -
This principle is really a statement of our aim in writing this book: Releasing software should be easy. It should be easy because you have tested every single part of the release process hundreds of times before. It should be as simple as pressing a button. The repeatability and reliability derive from two principles: automate almost everything, and keep everything you need to build, deploy, test, and release your application in version control. [Humble and Farley, 2011]
Neal Ford has also described the essence of Continuous Delivery as the need for authoritative, repeatable, automated checking of production readiness [Ford, 2015].
Conclusions / towards an improved architectural strategy
We should now recognize that -
- Repeatability and reliability are key architectural quality factors of a Continuous Delivery system
- The 'entire system' must be designed to permit automated checking of production readiness
- The 'entire system' comprises both functional and specification system elements (which includes the deployment pipeline)
These system qualities are inextricably linked with testability, defined in [IEEE 1990] -
(1) The degree to which a system or component facilitates the establishment of test criteria and the performance of tests to determine whether those criteria have been met
(2) The degree to which a requirement is stated in terms that permit establishment of test criteria, and performance of tests to determine whether those criteria have been met.
In a digital context, high-bar testability quality factors can also present game changing opportunities, e.g. canonical specification (input data containing no real user data), test-in-isolation and realistic stub approaches are key enablers for mobile device cloud testability, which drives direct value via enhanced usability and customer engagement.
...for a system to meet its acceptance criteria to the satisfaction of all parties, it must be architected, designed and built to do so - no more and no less [Rechtin, 1991]
What can we do to improve?
Neal Ford presents an overview of the architectural challenges posed by CD in Continuous Delivery for Architects [Ford, 2014]. He suggests that -
- Architects should be responsible for constructing the deployment pipeline
- It is an architectural concern to decide the number of stages for the deployment pipeline
Evaluating architectures for testability
One suggested approach would be to regularly re-draw the architecture with technical leads, and examine end-to-end testability and suitability for CD. If we weigh testability qualities of repeatability and reliability on the architecture, we can identify where we need to apply design tactics -
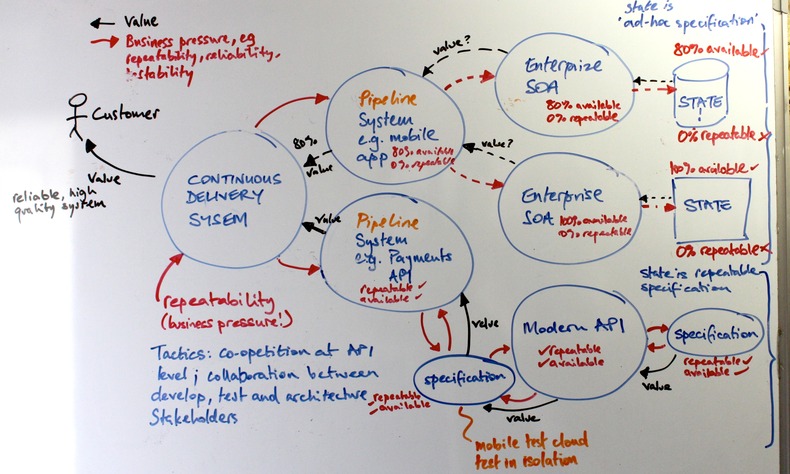 Scruffy whiteboard figure: Legacy systems with low testability drive down repeatability and reliability throughout the pipeline.
Scruffy whiteboard figure: Legacy systems with low testability drive down repeatability and reliability throughout the pipeline.
What does an 'ideal' system pipeline look like?
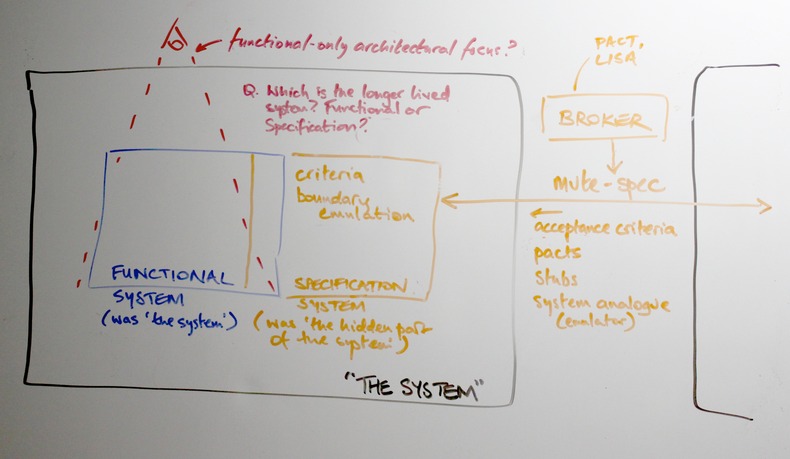
The test setup for a system is itself a system [Rechtin, 1991]
So, the first (hopefully now obvious) component of an ideal pipeline is the recognition of the need to apply a full-system design approach, to consider how the system will demonstrate its production readiness -
Next, if we imagine an 'ideal' system (in so far as testability is concerned), map out its 'Humble-Farley' pipeline, and focus on the types of testing that need to be performed at each stage, from this we can deduce a set of clear tensions placed by our system upon its boundaries -
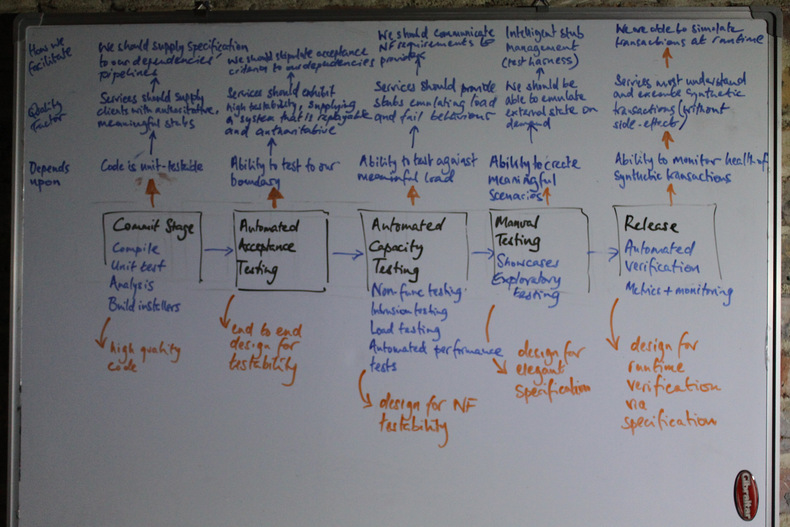 Scruffy whiteboard figure: Some things we might need to test at each stage in the deployment pipeline.
Scruffy whiteboard figure: Some things we might need to test at each stage in the deployment pipeline.
Pipeline Stage: Commit
Testability Quality Factor: Code is unit-tested
External System Testability: Services should supply consumers with authoritative, meaningful stubs
Our SLA: We supply specification to our dependencies' pipelines, to enable them to mature, e.g. a PACT.
Pipeline Stage: Automated Acceptance Testing
Testability Quality Factor: Ability to test reliably and repeatedly, to our boundary; in digital businesses, UI Journey Tests should be runnable in a remote mobile device cloud
External System Testability: Services should exhibit high testability, supplying a system that is reliable and authoritative, and if necessary, re-playable;
Our SLA: We should supply acceptance criteria to our dependencies' pipelines, rather than attempt to exhaustively test the entire world
Pipeline Stage: Automated Capacity Testing
Testability Quality Factor: Ability to test against meaningful load
External System Testability: Services should provide the ability to emulate full load and/or fail behaviour
Our SLA: We communicate non-functional requirements to providers as SLAs
Pipeline Stage: Manual Exploratory Testing
Testability Quality Factor: Ability to create meaningful scenarios
External System Testability: External services should emulate external state scenarios on demand
Our SLA: We agree intelligent stub management (or test harness)
Pipeline Stage: Release
Testability Quality Factor: Ability to monitor heath of production flows via measurement and metrics, as well as synthetic transactions
External System Testability: Services must handle synthetic transactions (without side-effect)
Our SLA: We, in turn, must be able to simulate synthetic transactions at runtime
Wow. That's a lot of testing and a lot of design needed to support that.
Testability Tactics
Setting and examining a program's internal state is an aspect of testing that will figure predominantly in our tactics for testability [Bass et al, 2013]
[Bass et al, 2013] present the following tactics and approaches -
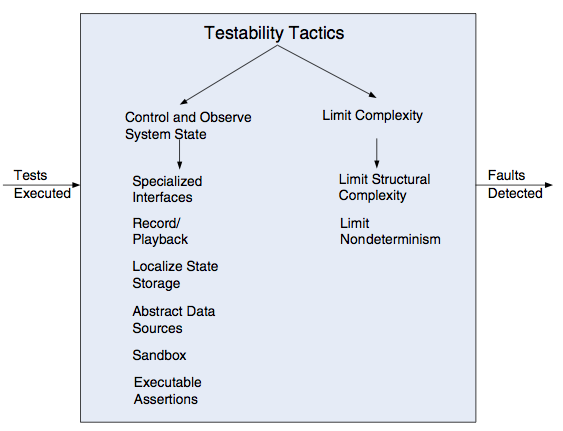
We summarize [Bass et al, 2013] as follows -
Control and Observe System State
In order to test a component, we must be able to control its internal state, simulate its inputs and observe the result. Special tactics for this include -
- Specialized interfaces - get / set / reset / report methods
- Record/playback - capturing information crossing an interface as well as using it as input for further testing (e.g. using log-time code generation)
- Localize state storage - in order to start a component in an arbitrary state for a test, complex distributed state must be localized, perhaps by externalizing system state to a tracking state machine
- Abstract data sources - in the same way it is advantageous to control a component's state, controlling a component's input data makes it easier to test
- Sandboxing and virtualized resources - isolating the system under test from the outside world, so that we enable experimentation without the worry that we may have to undo the consequences of the test; by isolating our system, we enable transactional teardown; fully virtualized resources allow us to test complex scenarios, e.g. the effect of changing server time zones or cultures.
- Executable assertions - by validating data values when values are read or modified, we provide defect localization
For each tactic, we must implement by enhancing existing functional code with testing additions. [Bass et al, 2013] suggest this can be implemented in a variety of ways, e.g.
* Component substitution - use IoC to swap out with a test-friendly implementation
* Pre-processor macros - when activated, enable reporting in production
* Aspects - allows us to add cross-cutting state reporting, e.g. at repository boundaries
Limit Complexity
The second tactic identified by [Bass et al, 2013] is that we should limit complexity because 'complex software is harder to test', they suggest that this arises because it is more difficult to recreate a 'large state space' and make its behaviour repeatable.
- Limit structural complexity Use separation of concerns, low coupling and SOLID as a means to ensure we can test in isolation. Furthermore, architectural styles such as layered architectures can help us test individual concerns in isolation from other layers
- Limit nondeterminism "The counterpart to limiting structural complexity is limiting behavioural complexity... when it comes to testing, nondeterminism is a very pernicious form of complex behaviour'"
This makes sense - it's also the reason that Single Responsibility Principle and separation of concerns (DRY) results in far less complex tests, as component orthogonality means there are far fewer (aka. far less complex) permutations of state to be handled.
A final word from [Bass et al, 2013] on tactics around test suites (harnesses), and writing tests first -
- A vehicle often used to execute the tests is the test harness. Test harnesses are software systems that encapsulate test resources such as test cases and test infrastructure so that it is easy to reapply tests across iterations
- Another vehicle is the creation of test cases prior to the development of a component, so the developers know which tests their component must pass
Other suggested tactics
- Trial PACT-based specification approaches, as a means to allow services to evolve independently from one another; Provider States effect test-harness duties for PACT based specification systems
- Pair with internal service and framework teams to help them write consumer acceptance tests first, rather than focus on internal unit tests; they should encourage their consumers to be able to clone and run acceptance tests, as well as make pull requests such that new specifications can be added
- Service providers can use automated acceptance tests to generate canonical, reusable state scenarios based upon recorded system state, to minimize rework by consumers (which leads to specification gap)
- 'Consumer tests' should be runnable against either predefined stubs (asserting detailed results) or live data (where only generic assertions can be made)
- Each integration point should have a single gateway proxy and associated unit and integration tests; if the remote system supports state injection, a test fixture model can be created alongside tests, to manage the external fixture (see [Meszaros, 2007])
- Gateway pattern proxies should be re-configurable, to act as diagnostic play / replay points (perhaps even, performing code generation of realistic stubs)
- Where we need to limit nondeterminism in test systems, we can use generated stubs to inject known a fixed input, such that we can repeatedly assert a known result (e.g. we can replay a specific instant in time)
- Modular, pluggable IoC architectures enable composition and dynamic configuration at runtime, as well as provide some level of process isolation. With event sourcing, this enables parallel actors, A/B comparison, injection of diagnostic filtering, handlers for synthetic transactions, etc.
- Collaborate - involve development technical leads in all architecture discussions
Estimates vary, but flawed setup at launch sites and other remote test sites have been responsible for tens of percent of failures observed during test. Yet seldom is the test setup shown on the block diagram of the system to be tested. Few architectures specify the appropriate test setup, yet the latter is a major element and presents a critical interface to the system [Rechtin, 1991]
Materials
[Bass et al, 2013] Software Architecture in Practice (3rd Edition) (SEI Series in Software Engineering), Len Bass, Paul Clements, Rick Kazman, Addison-Wesley, 2013.
[Cohn, 2010] Succeeding With Agile, Software Development Using Scrum, Mike Cohn, Addison-Wesley, 2010.
[Meszaros, 2007] xUnit Test Patterns - Refactoring Test Code, Gerard Meszaros, Addison-Wesley, 2007.
[Ford, 2014] Continuous Delivery for Architects,Neal Ford
[Ford, 2015] Engineering Practices for Continuous Delivery, Neal Ford [pdf]
[IEEE 1990] IEEE Computer Society. IEEE Standard Computer Dictionary: A
Compilation of IEEE Standard Computer Glossaries, 610. New York,
N.Y.: Institute of Electrical and Electronics Engineers, 1990.
[O'Brien et al, 2005] Quality Attributes in Service-Oriented Architectures, O'Brien, Bass, Merson, 2005.
[Rechtin, 1991] Systems Architecting, Creating and Building Complex Systems, Eberhardt Rechtin, Prentice Hall, 1991.
Lean Agile Architecture and Development